Edit : Writing to delta is now substantially easier, and you don’t need to pass credential
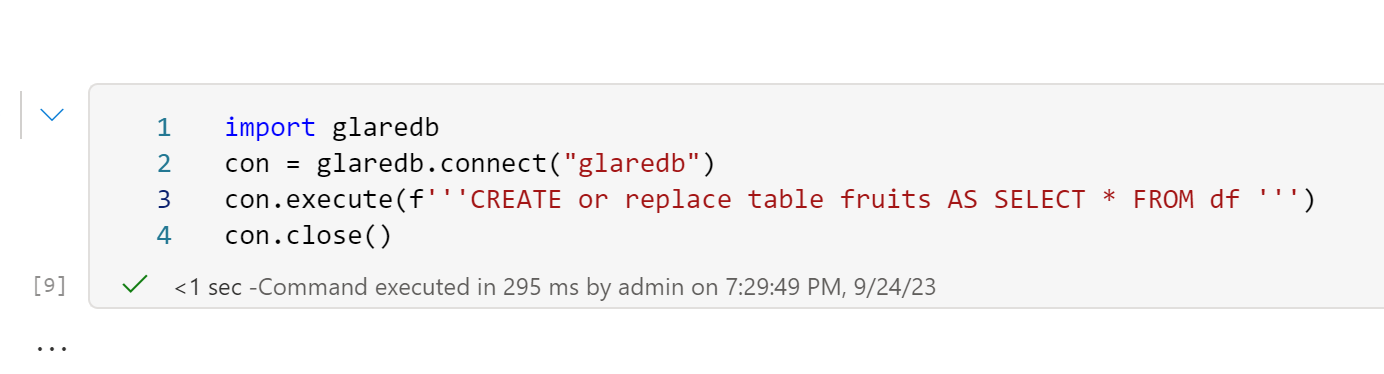
from deltalake.writer import write_deltalake write_deltalake("abfss://xxxxx@onelake.dfs.xx",df,mode='overwrite')TL;DR : you can load data to Fabric managed table area using the Python Package Delta-rs, (internally it is written in Rust) it is very handy when Spark is not the appropriate Solution for example in cloud functions where resources are very limited.
Load Files to Delta Tables using abfss
In this code, we use Pyarrow Dataset to list multiple folders and Load it as a Delta Table using Delta Rust, because we are using a URL, we can save data anywhere in any workspace assuming we have write access to, notice as of today, Pyarrow don’t support OneLake URL yet, so you need to read it from a mounted Lakehouse
import pyarrow.dataset as ds
from deltalake.writer import write_deltalake
aadToken = notebookutils.credentials.getToken('storage')
storage_options={"bearer_token": aadToken, "use_fabric_endpoint": "true"}
sf=100
rowgroup = 2000000
nbr_rowgroup_File = 8 * rowgroup
for tbl in ['lineitem','nation','region','customer','supplier','orders','part','partsupp'] :
print(tbl)
dataset = ds.dataset(f'/lakehouse/default/Files/{sf}/{tbl}',format="parquet")
write_deltalake(f"abfss://xxxxx@onelake.dfs.fabric.microsoft.com/yy.Lakehouse/Tables/{tbl}"\
,dataset\
,mode='overwrite',overwrite_schema=True,max_rows_per_file =nbr_rowgroup_File,min_rows_per_group=rowgroup,max_rows_per_group=rowgroup\
,storage_options=storage_options)Load Files to Delta Tables using mounted Lakehouse
Alternatively, if you mount a lakehouse you can use something like this
write_deltalake(f"/lakehouse/default/Tables/name",df,engine='rust',mode="append", storage_options={"allow_unsafe_rename":"true"})Note : rowgroup size is just for information, that’s a whole different topic for another day 🙂
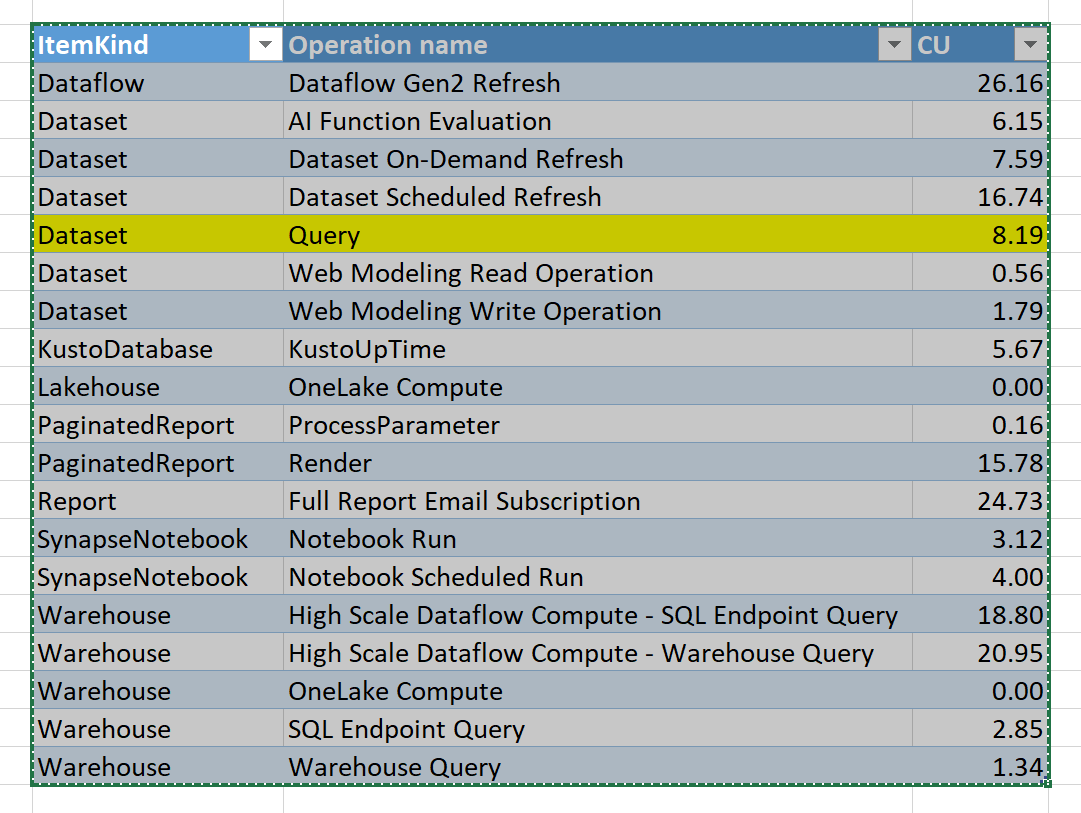
I did use it to Load 38 GB of compressed Parquet files, and it did work fine, Both SQL and Vertipaq did run Queries without problem.

There are still some Bugs
Because Fabric in-house Engines (Vertipaq, SQL etc) are tested using Delta Tables generated by first party tools (Spark, DF Gen2) you may find some incompatibility issues when using Delta Rust, Personally I did find that Vertipaq does not support RLE_Dictionnary, and some issues with SQL Engine which I can’t easily reproduce, although it works fine with Fabric Spark ( I did report the bug )
How About V-Order ?
V Order is a Microsoft proprietary tech, so it can’t be used here. From my testing, V Order produces better compressed Parquet files by altering the sort orders of columns, so unfortunately if you use Delta Rust you lose that.
Final Thoughts
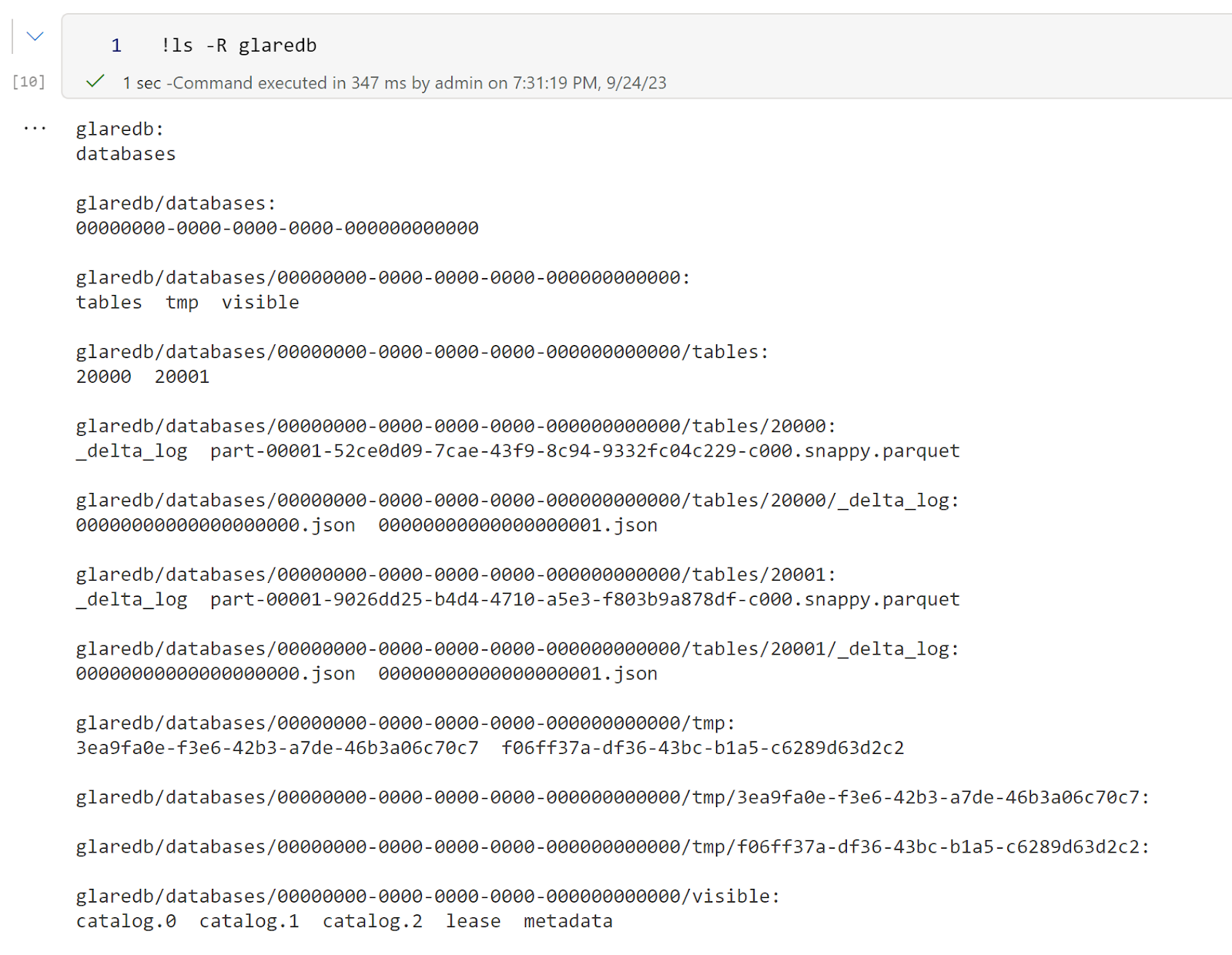
One of the first questions about Fabric I got from some skeptical audience was; How Open is it ? and to be honest I had my doubts too, turns out it is just Azure Storage with a custom URL, and it is Just Delta Table under the hood.
I would like to thank Josh and Matt for adding this feature to Delta Rust.