Introduction
Was listening to this short Video (Fabric Espresso: Will Fabric replace Azure Synapse?) and the VP of Synapse described Fabric as the OS for analytics, and I think it is not simply marketing talk but they are into something, This short blog will show that using DuckDB in Fabric maybe a useful scenario.
OneLake Throughput is the unsung hero of Fabric
I tried to run DuckDB before in the cloud and all the systems I used Google Colab, Cloud functions, AWS Sagemaker etc have the same limitation, The throughput from the remote storage is just too slow, Fabric Onelake which is based on Azure ADLS Gen2 has an amazing throughput see this example
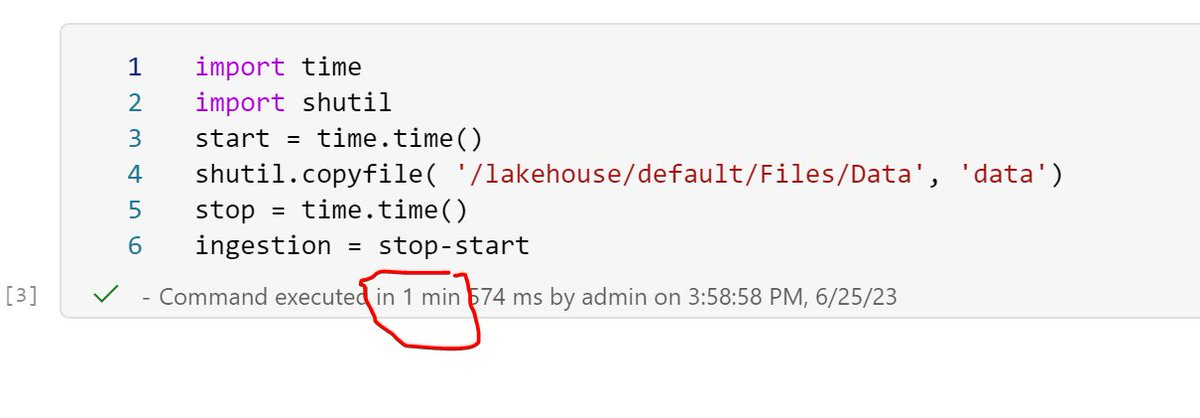
The file size is 26 GB , that’s nearly 433 MB/s, this is simply amazing, as a reference last week I bought one of those cheap USB flash drives and the read speed was 132 MB/s.
DuckDB reading Directly from Remote Storage
DuckDB is very fast when reading from a VM SSD especially when using the proprietary file format, but realistic speaking users in fabric would probably be more interested in reading directly from the Delta table, so I avoided creating another copy with DuckDB storage file.

I test two approaches
- Import the data into Memory and than run the queries
- Run the queries Directly from OneLake
The script is available here, the main Table is rather small 60 million rows, I am using just 4 cores, and the results are very interesting

32 second to import to Memory this includes decompressing and rewriting the data using DuckDB format (in RAM), but it is done only once.
24 seconds to run the Queries using 4 cores, just to give you an idea , another famous lakehouse vendor when using the same data, The Engine requires 16 cores and finishes the queries in around 40 seconds.
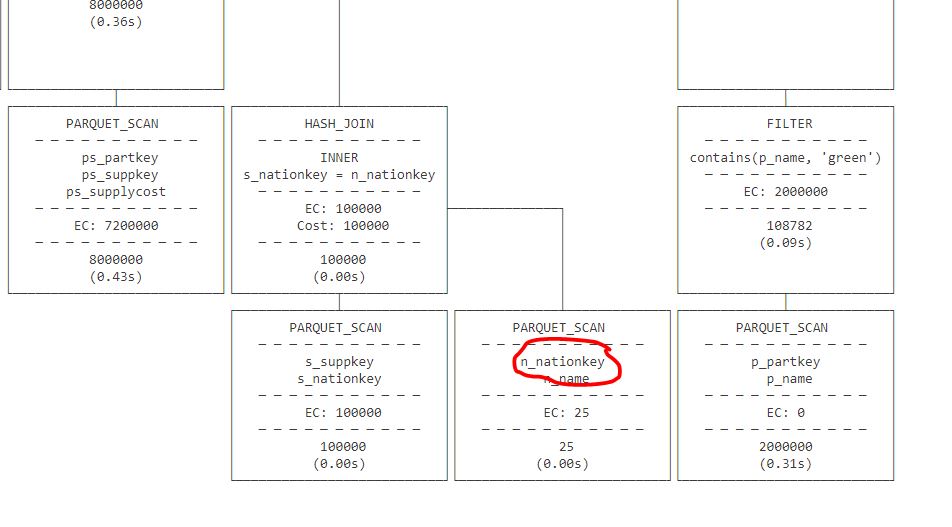
Running the queries directly from OneLake took 58 seconds, I notice though that Query 9 is particularly slow, which usually means a bad query Plan.
I run a profile on that Query and indeed when running directly from Parquet, DuckDB got the join order wrong, as DuckDB ignore the stats when reading from Parquet ( according to the dev, most stats in parquet are wrong anyway)

Note : I use Delta lake package to get the correct list of Parquet files to read, you can read directly from Delta using arrow dataset but it is slower.
Take away
In The medium term, we can imagine Fabric supporting More Engines. There is already some talks about SQL Server (although Parquet is not designed for OLTP, but that’s another subject) The storage layer which is the foundation for any analytical work is very solid, the Throughput is very impressive, let’s just hope we get a lighter VM to run smaller workloads.
DuckDB currently does not support Buffer pool when reading from remote storage, I am afraid they need to add it. Microsoft supporting Delta has changed the market dynamic and DuckDB can’t ignore it. Parquet alone is not enough, we need those Delta stats for better Query plans.
