It is trick I learn today and thought it maybe useful to share, I have a folder of parquet files, partitioned by day using Hive style, the data is ingested every 5 minutes which end up generating 288 small parquet files per day, it is rather nice for a write scenario but reading that data will be slow as it generate a big overhead opening individual files, it is a well documented problem, and more sophisticated table format like Delta Table and Iceberg fix the problem by using compaction, but it does not work with Python. ( Edit by Python, I mean Engine Like Data Fusion, DuckDB , Pandas not Spark which does not make sense for a small Dataset)
In my example I use Only Python and pyarrow dataset which does not support compaction, but maybe there is a solution.
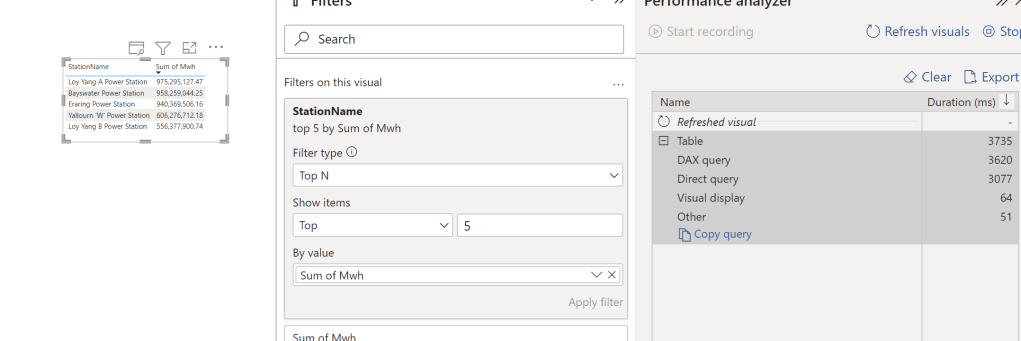
Just for illustration, here is a view of my Bucket in Cloudflare R2 (Pyarrow support S3, GCP and Azure)

Warning : the code will delete existing files, use at your own risk
- Read the existing partitions except today data, as you may end up having concurrent Write , which will corrupt your table.
- Filter only the partitions that contains more than 1 file , something like this Using DuckDB
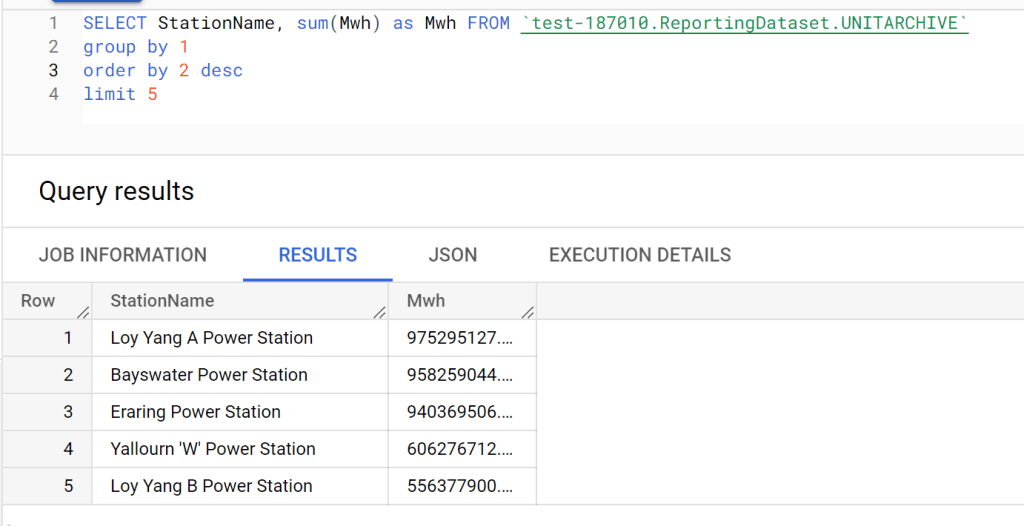
create view base as select * from parquet_scan('s3://delta/aemo/scada/data/*/*.parquet' , HIVE_PARTITIONING = 1,filename=1) where Date < '{cut_off}';
create view filter as select Date, count(distinct filename) as cnt from base group by 1 having cnt>1
- Read the data using the previous filter, again, we are not touching today Partition to avoid any conflicts
tb=con.execute('''select SETTLEMENTDATE,DUID,SCADAVALUE,file,cast(base.Date as date) as Date from base inner join filter on base.Date= filter.Date''').arrow()
- Write Back the Data using Pyarrow Dataset with the option ‘delete_matching’
ds.write_dataset(xx,"delta/aemo/scada/data/", filesystem=s3,format="parquet" , partitioning=['Date'],partitioning_flavor="hive",
min_rows_per_group=120000,existing_data_behavior="delete_matching")
Again there is no support for transaction, if your code for whatever reason, did not complete, you will end up with unstable table
- And here is the results, all old partitions have only 1 file

You need to run the Job only once a day, hopefully next year sometimes, either Apache Iceberg or Delta Table will provide compaction for the Python client, in the meantime maybe this approach is good enough :), you can see the full code here
Another approach is copy on write, basically every time you ingest a new data, you need to copy the existing data append it to the new data and overwrite existing files, but it maybe an expensive operation, specially if your job runs more frequently.