TL;DR, we use filepath() function to get the partition Data which can be passed from PowerBI when used with Synapse Serverless, Potentially Making substantial cost saving when used in Incremental refresh as less files will be scanned.
Edit : there is another Technique to incrementally load parquet files without a Database
This blog is just me experimenting with the possibility of passing the filters from PowerBI to a Parquet file using Synapse Serverless.
when you deal with On demand Query engine Like Athena, BigQuery, Synapse Serverless etc, the less files read, the less cost incurred, so if somehow you manage to read only the files that contain the data without scanning all your folders, you can make substantial saving.
To Be clear, the first time I used Parquet was yesterday, so I have very basic knowledge at this stage.
1- Get the Source Data
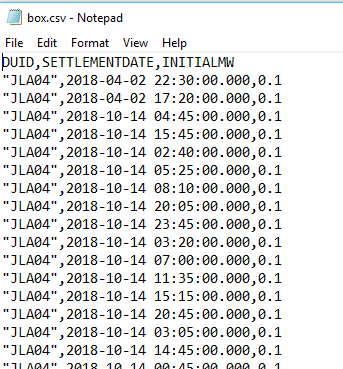
I have a csv file with 3 Millions rows, here is the schema
2- Partition The Data
as far as my understanding of Synapse Serverless engine, when you filter by date for example, The engine will scan the whole file, maybe if the column is sorted, it will scan less data, I don’t know and have not try it yet, instead we are going to partition the Table by date, which is simply generating lot of files split by the date values, I imagine generating a lot of small files is not optimal too, it will reduce cost but potentially making the Query slower ( at the last this how other Engine Works).
I am using this python script to generate the partitions
import pandas as pd
import datetime
df = pd.read_csv('box.csv',parse_dates=True)
df['SETTLEMENTDATE'] = pd.to_datetime(df['SETTLEMENTDATE'])
df['Date'] = df['SETTLEMENTDATE'].dt.date
df.to_parquet('nem.parquet',partition_cols=['Date'],allow_truncated_timestamps=True)
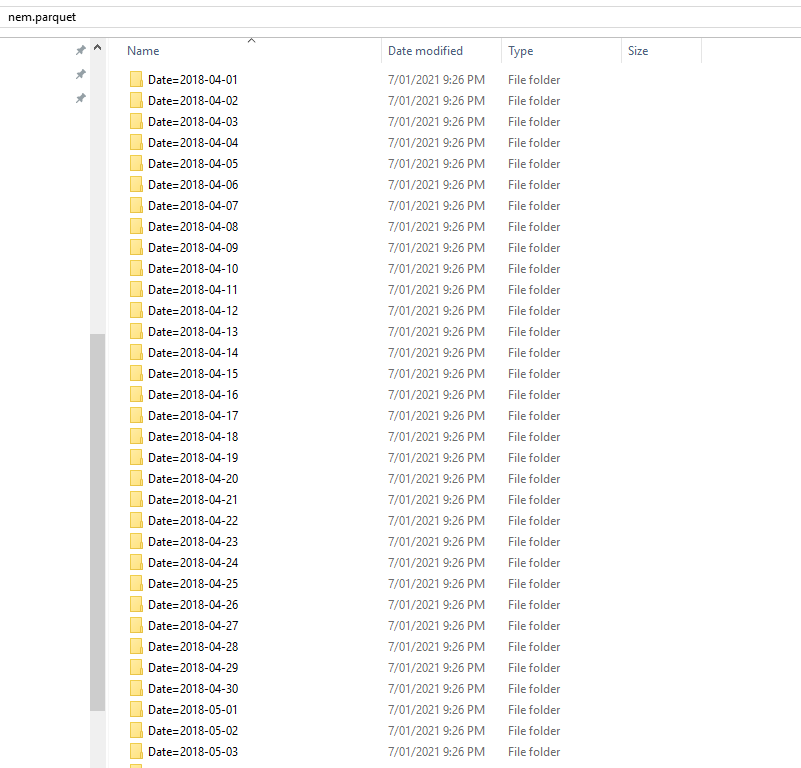
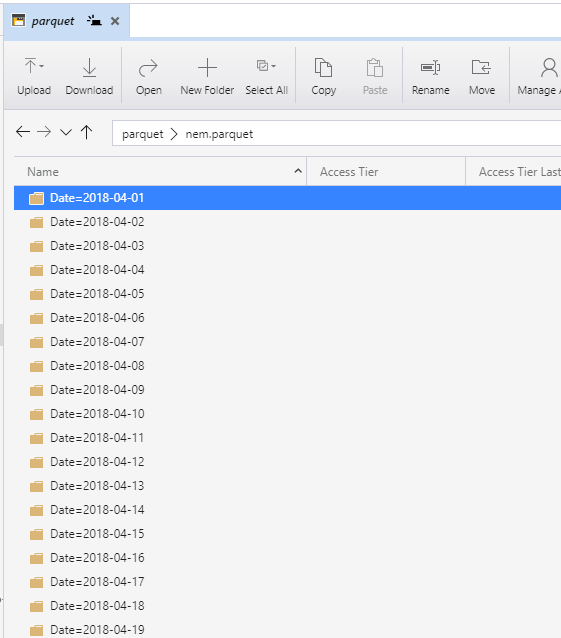
and here is the results, a folder of parquet files grouped by Date
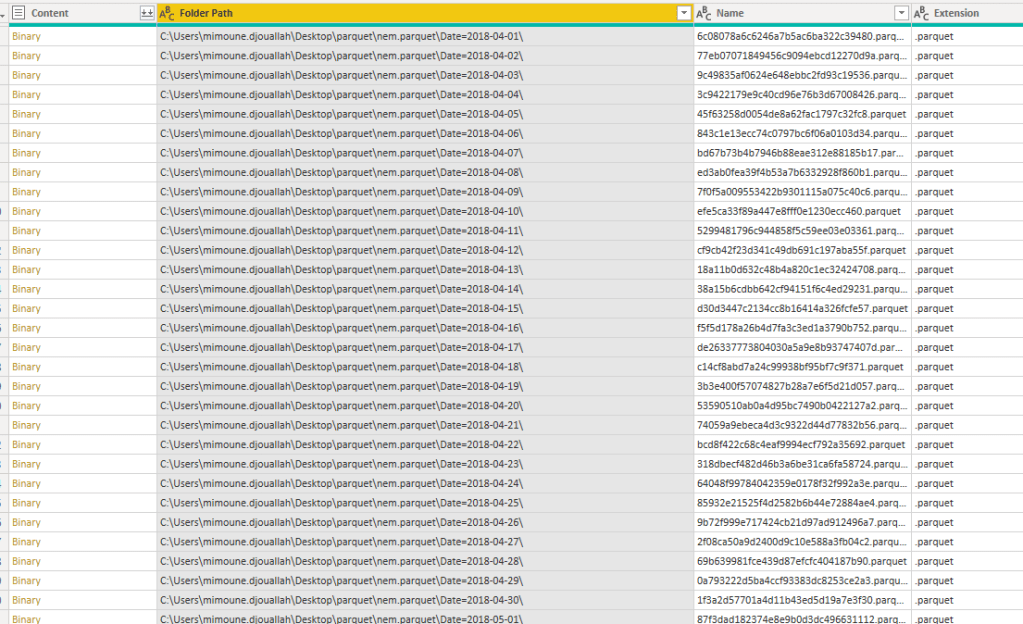
which I can read using the PowerBI Desktop
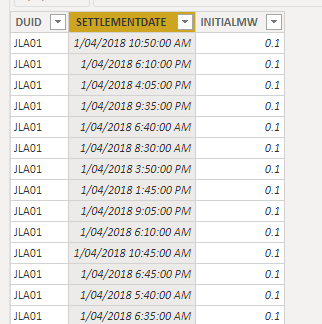
I just casually read a parquet file, without any Programing Language !!! ( Kudos for the Product team), this is only to test the parquet is properly generated.
3- Load The files to Azure Storage
This is only a show case, but in a production workflow, you maybe using something like ADF or Python Cloud Functions, anyway to upload a lot of files, I am using Azure storage explorer
now we can start using Synapse Analytics
4- Create a View In Synapse Serverless
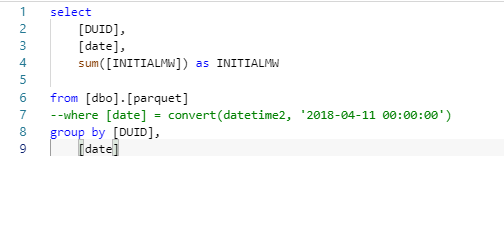
we are going to leverage filepath() function to get the partition date, please see the documentation , here is the Query to create a view
USE [test]; GO DROP VIEW IF EXISTS parquet; GO CREATE VIEW parquet AS SELECT *,convert(Datetime,result.filepath(1),120) as date FROM OPENROWSET( BULK 'https://xxxxxxxxxx.dfs.core.windows.net/parquet/nem.parquet/Date=*/*.parquet', FORMAT='PARQUET' ) result
5- Test if the filter Partition Works
Let’s try some testing to see how much is scanned
no Filter, scan all the files, data processed 48 MB

now with filter , only Date 11/04/2018, Data processed 1 MB

6- Test in PowerBI
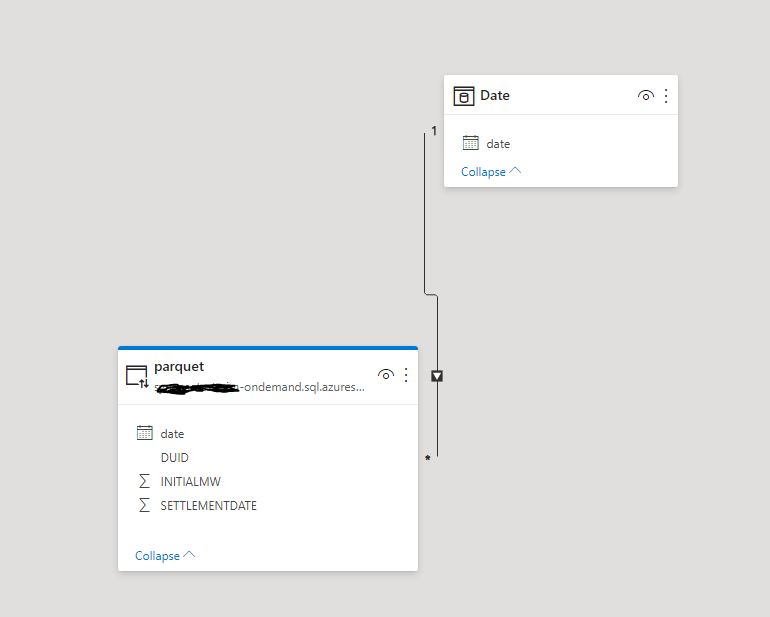
I build this small model, Date Table is import and Parquet is DirectQuery ( be cautious when using DirectQuery, PBI can be very chatty and generate a lot of SQL Queries, Currently, it is better to use only import mode, until cache support is added)
Case 1: View all Dates
Data Processed : 43 MB

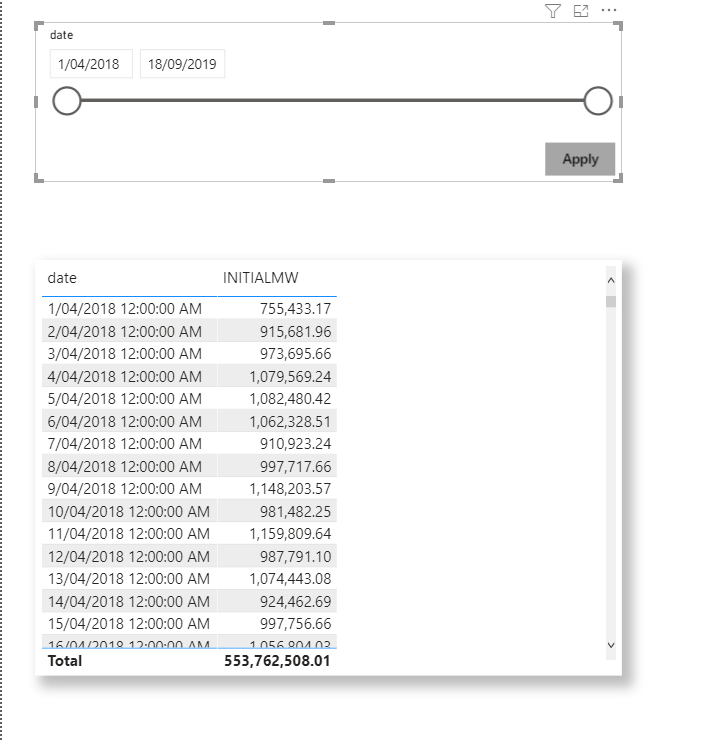
Case 2: Filter Some Dates
let’s filter only 2 days
Note : please use Query reduction option in PowerBI desktop, otherwise, every time you move the slicer, a query will be generated

Here is the result

I was really excited when I saw the results: 1 MB Synapse Serverless was smart enough to scan only 2 files
7- Incremental Refresh
Instead of Direct Query, let’s try a more practical use case, I configured Incremental refresh to change dates only for the Last 3 days
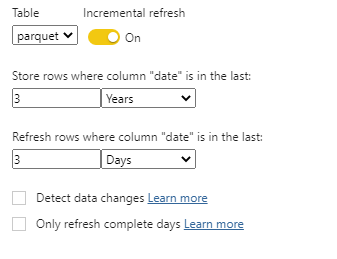
and here is the List of Queries generated by PowerBI
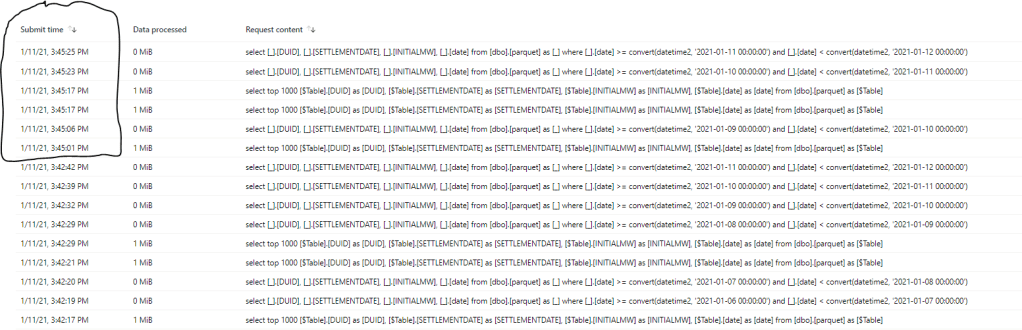
I have only Data for 2018 and 2019, the second refresh (that Started at 3:45 PM) just refreshed the data for the Last three days and because there is no files for those dates the Query returned 0 MB, which is great.
Another Nice functionality is select top 100 which is generated by PowerQuery to check field type scanned only 1 MB !!!!
Just to be sure, I have done another refresh at 4 :24 PM and checked the Partitions using SSMS
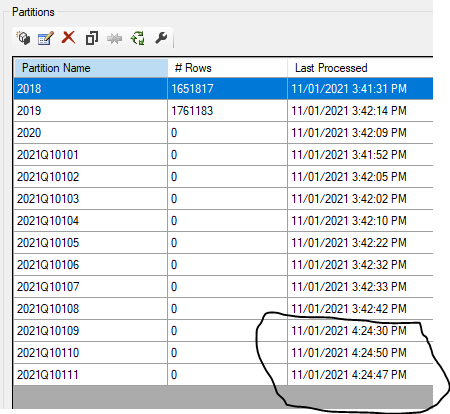
Only the last three partions were refreshed and PQ sent only 6 Queries ( 1 select data for 1 day and the other check field type)
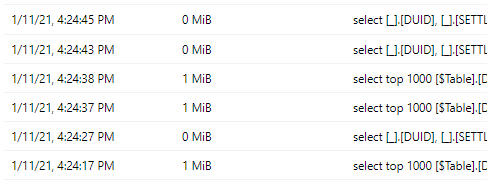
I think Azure storage + Synapse analytics Serverless + PowerBI Incremental Refresh may end up as a very powerful Pattern.

Mim, very clever, will this work with an incremental refresh? In this section:
‘6- Test in PowerBI
I build this small model, Dim Table is import and Parquet is DirectQuery ‘ should ‘Dim Tabel be ‘Date Table’?
LikeLike
Thanks Mike, I updated the Blog with testing of Incremental refresh, yes it works and Updated only the Latest Data.
LikeLike
I’m very impressed, this makes me look a Synapse in a new light
LikeLiked by 1 person
Hi thaanks for sharing this
LikeLiked by 1 person
Thank You !!!
LikeLike