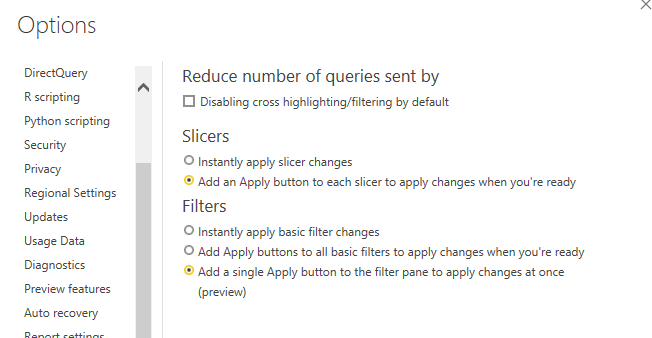
Recently I come across a new use case, where I thought Azure Synapse serverless may make sense, if you never heard about it before, here is a very good introduction
TLDR; Interesting new Tool !!!!, will definitely have another serious look when they support cache for the same Queries
Basically a new file arrive daily in an azure storage and needs to be processed and later consumed in PowerBI
The setup is rather easy, here is an example of the user interface, this is not a step by step tutorial, but just my first impression.

I will use AEMO (Australian electricity market Operator) data as an example, the raw data is located here
Load Raw Data
First I load the csv file as it is, I define the columns to be loaded from 1 to 44 , make sure you load only 1 file to experiment then when you are ready you change this line
'https://xxxxxxxx.dfs.core.windows.net/tempdata/PUBLIC_DAILY_201804010000_20180402040501.CSV', 'https://xxxxxxxx.dfs.core.windows.net/tempdata/PUBLIC_DAILY_*.CSV',
Then it will load all files, notice when you use filename(), it will add a column with the files name, very handy
USE [test]; GO DROP VIEW IF EXISTS aemo; GO CREATE VIEW aemo AS SELECT result.filename() AS [filename], * FROM OPENROWSET( BULK 'https://xxxxxxxx.dfs.core.windows.net/tempdata/PUBLIC_DAILY_201804010000_20180402040501.CSV', FORMAT = 'CSV', PARSER_VERSION='2.0' ) with ( c1 varchar(255), c2 varchar(255), c3 varchar(255), c4 varchar(255), c5 varchar(255), c6 varchar(255), c7 varchar(255), c8 varchar(255), c9 varchar(255), c10 varchar(255), c11 varchar(255), c13 varchar(255), c14 varchar(255), c15 varchar(255), c16 varchar(255), c17 varchar(255), c18 varchar(255), c19 varchar(255), c20 varchar(255), c21 varchar(255), c22 varchar(255), c23 varchar(255), c24 varchar(255), c25 varchar(255), c26 varchar(255), c27 varchar(255), c29 varchar(255), c30 varchar(255), c31 varchar(255), c32 varchar(255), c33 varchar(255), c34 varchar(255), c35 varchar(255), c36 varchar(255), c37 varchar(255), c38 varchar(255), c39 varchar(255), c40 varchar(255), c41 varchar(255), c42 varchar(255), c43 varchar(255), c44 varchar(255) ) AS result
The previous Query create a view that read the raw data
Create a View for a Clean Data
As you can imagine , Raw data by itself is not very useful, we will create another view that reference the raw data view and extract a nice table ( in this case the Power generation every 30 minutes)
USE [test]; GO DROP VIEW IF EXISTS TUNIT; GO CREATE VIEW TUNIT AS select [_].[filename] as [filename], convert(Datetime,[_].[c5],120) as [SETTLEMENTDATE], [_].[c7] as [DUID], cast( [_].[c8] as DECIMAL(18, 4)) as [INITIALMW] from [dbo].[aemo] as [_] where (([_].[c2] = 'TUNIT' and [_].[c2] is not null) and ([_].[c4] = '1' and [_].[c4] is not null)) and ([_].[c1] = 'D' and [_].[c1] is not null)
Connecting PowerBI
Connecting to azure synapse is extremely easy, PowerBI just see it as a normal SQL server.
here is the M script
let
Source = Sql.Databases("xxxxxxxxxxx-ondemand.sql.azuresynapse.net"),
test = Source{[Name="test"]}[Data],
dbo_GL_Clean = test{[Schema="dbo",Item="TUNIT"]}[Data]
in
dbo_GL_Clean
And the SQL Query generated by PowerQuery ( which Fold)
select [$Table].[filename] as [filename], [$Table].[SETTLEMENTDATE] as [SETTLEMENTDATE], [$Table].[DUID] as [DUID], [$Table].[INITIALMW] as [INITIALMW] from [dbo].[TUNIT] as [$Table]
Click refresh and perfect, here is 31 files loaded
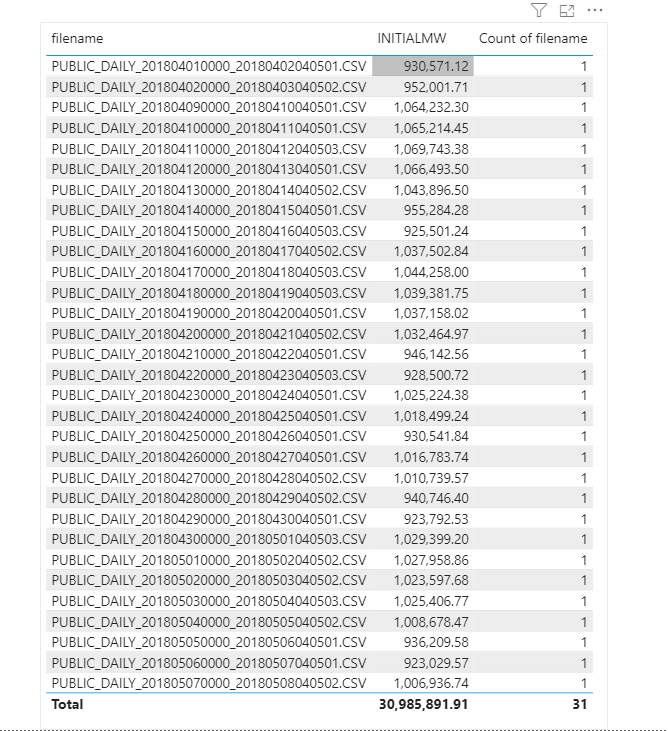
Everything went rather smooth, nothing to set up and I have now an Enterprise Grade Data warehouse in Azure, how cool is that !!!
How Much it cost ?
Azure Synapse serverless pricing model is based on how much data is processed
First let’s try with only 1 file ,running Query from the Synapse Workspace, the file is 85 MB, good so far, data processed is 90 MB, file size + some meta Data
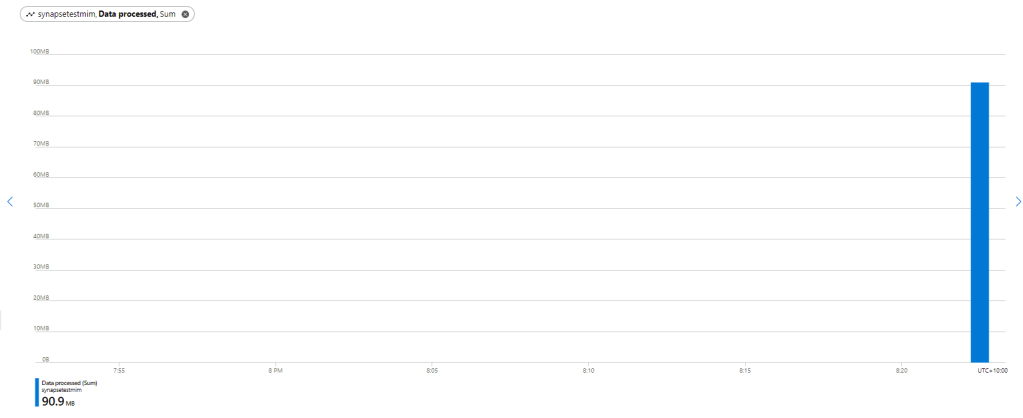
now let’s see using the Queries generated by PowerBI, in theory my files size are 300 MB, I will be paying only for 300 MB, let’s have a look at the Metrics

My first reaction was, there must be a bug , 2.4 GB !!!, I refreshed again and it is the same number !!!
A look at the PowerQuery diagnostic and a clear picture emerges, PowerBI SQL Connectors is famous for being “Chatty”, in this case you would expect PowerQuery to send only 1 Query but in reality it will send multiple Queries , at least 1 of them to check the top 1000 rows to define the fields type.
Keep in mind Azure Synapse Serverless has no cache ( they are working on it), so if you run the same query multiple times even with the same data, it will “scan” the files multiple times, and as there is no data statistic a select 1000 rows will read all files even without order by.
Obviously, I was using import mode, as you can imagine using it with directQuery will generate substantially more queries.
Just to be sure I tried to do refresh on the service.
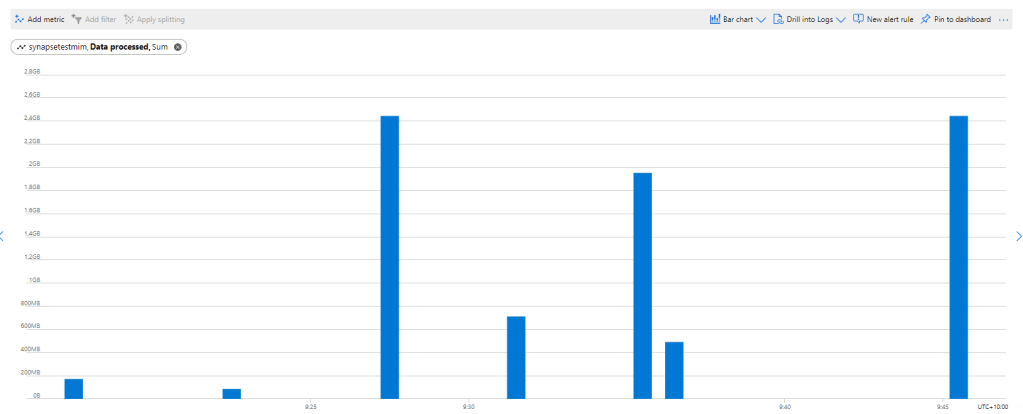
The same, it is still 2.4 GB, I think it is fair to say, there is no way to control how many time PowerQuery send a SQL Query to Synapse.
Edit 17 October 2020 :
I got a feedback that probably my PowerBI desktop was open when I run the test in the service, turn out it is true, I tried again with The desktop closed and it worked as expected, one refresh generate 1 query
Notice even if the CSV file was compressed, it will not make a difference, Azure synapse bill uncompressed data.
Parquet file would made a difference as only columns used would be charged, but I did not want to used another tool in this example.
Take Away
It is an interesting Technology, the integration with Azure cloud storage is straightforward, the setup is easy,you can do transformation using only SQL, Pay only what you use and Microsoft is investing a lot of resources on it.
But the lack of cache is a show stopper !!
I will definitely check it again when they add the cache and cost control, after all it is still in Preview 🙂