I was messing around with GlareDB which is one of the new wave of OLAP DB system (With DuckDB, Datafusion and Databend) it is open source and based on Datafusion, this blog is not a review but just a small demo for an interesting design decision by GlareDB developers, Instead of building a new storage system from scratch, they just used Delta Table, basically they assembled a database using just existing components, apparently all glued together using Apache Arrow !!!
Write Data using GlareDB
I am using Fabric Notebook here, currently writing to the Lakehouse does not work ( I opened a bug report, hopefully it is an easy fix) instead I will just the local folder
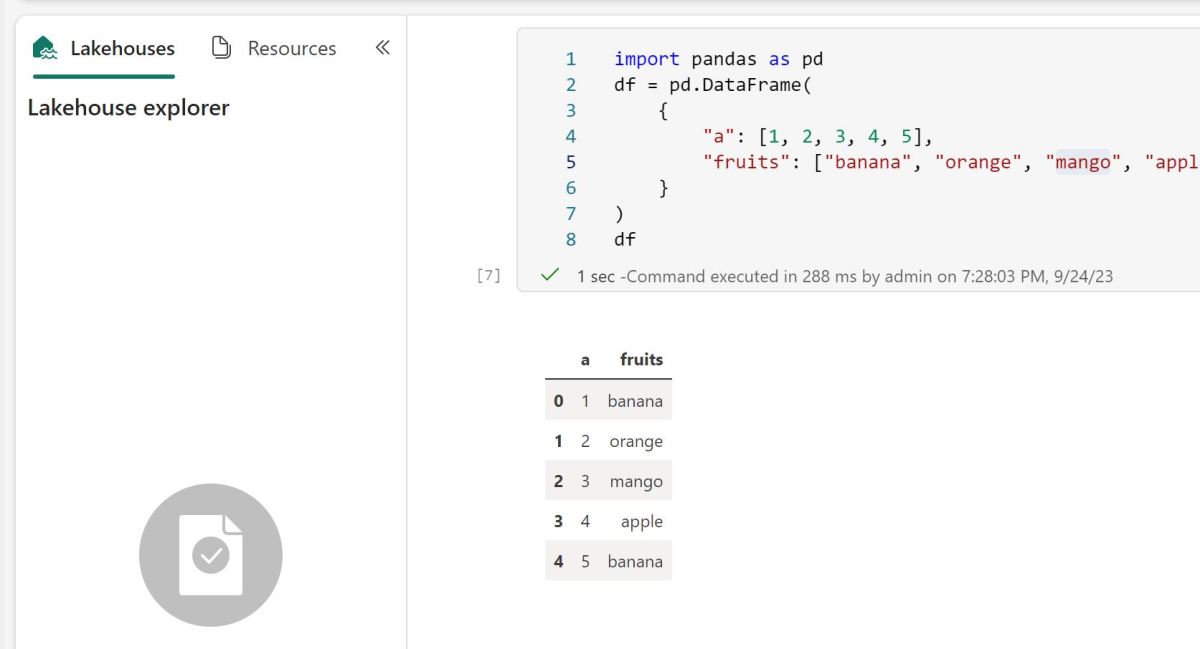
Let’s create a small dataframe using Pandas

GlareDB can query Pandas DF directly
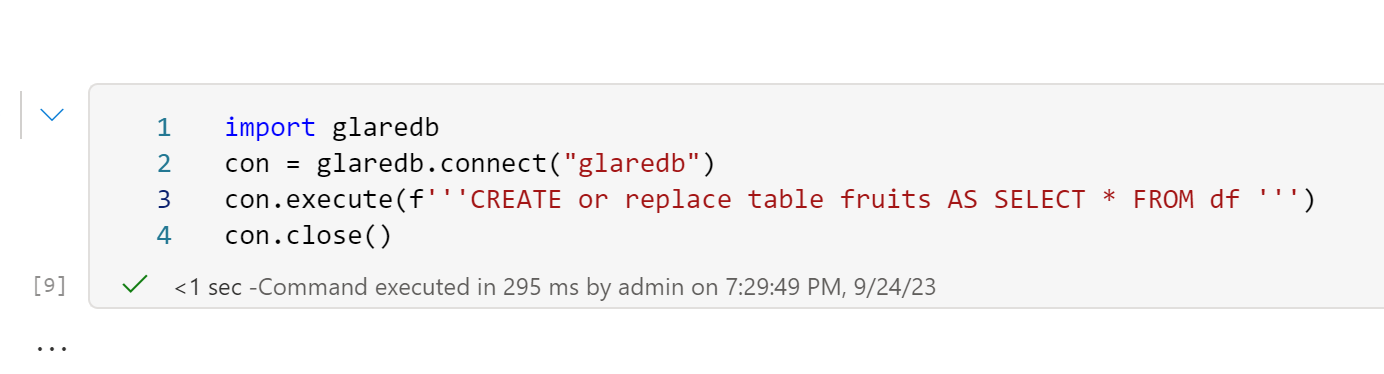
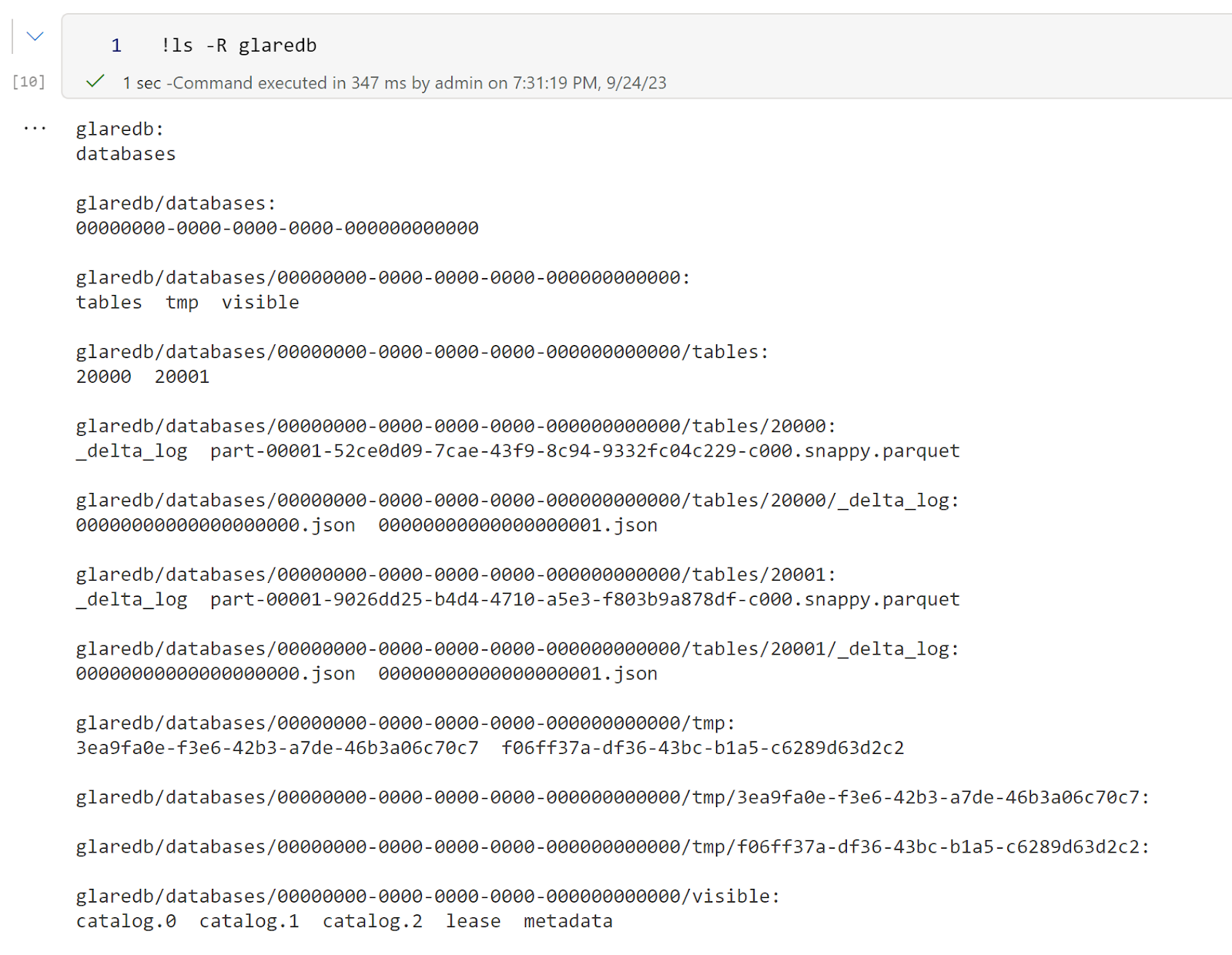
Then I can see the list of files
Read Data using Polars
Now the interesting part, because it is an Open Table Format, I can use another Engine to read the data, let’s try Polars for a change 🙂

It will be nice though to have a Query that return all tables with their path as tables/20001 does not mean much
So DB Vendors should stop innovating in Storage Format?
I have to admit I changed my mind about this subject, I used to think Query Engines Developers should design the best format that serve their Engine, after using Fabric for a couple of Months, open table format is just too convenient, my current thinking, the cold storage table format make a lot of of sense when using a standard format (Delta, Iceberg, Hudi etc) the optimization can be done downstream, for example tables statistics, In-Memory representations of the data, there are plenty of areas where DB vendor can differentiate their offering, but cold storage is really the common denominator.
One thing though I like about Delta is the relative Path. You can move around the folder and data keeps just working. In the current example, I moved the folder to my desktop and it still works. Iceberg is a bit tricky as it does not support relative paths yet.
