TL:DR; Although all fabric Engines can use the same Storage, the usage cost of every Engine is different and contrary to common wisdom , PowerBI Engine (Vertipaq) is not the most expensive.
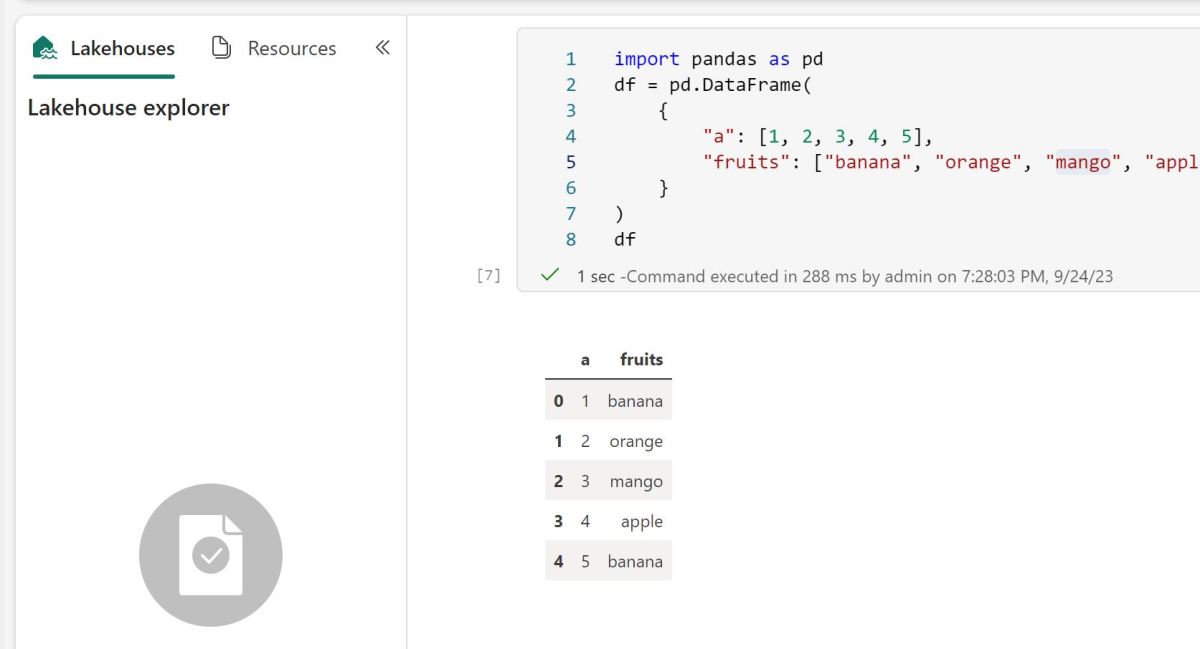
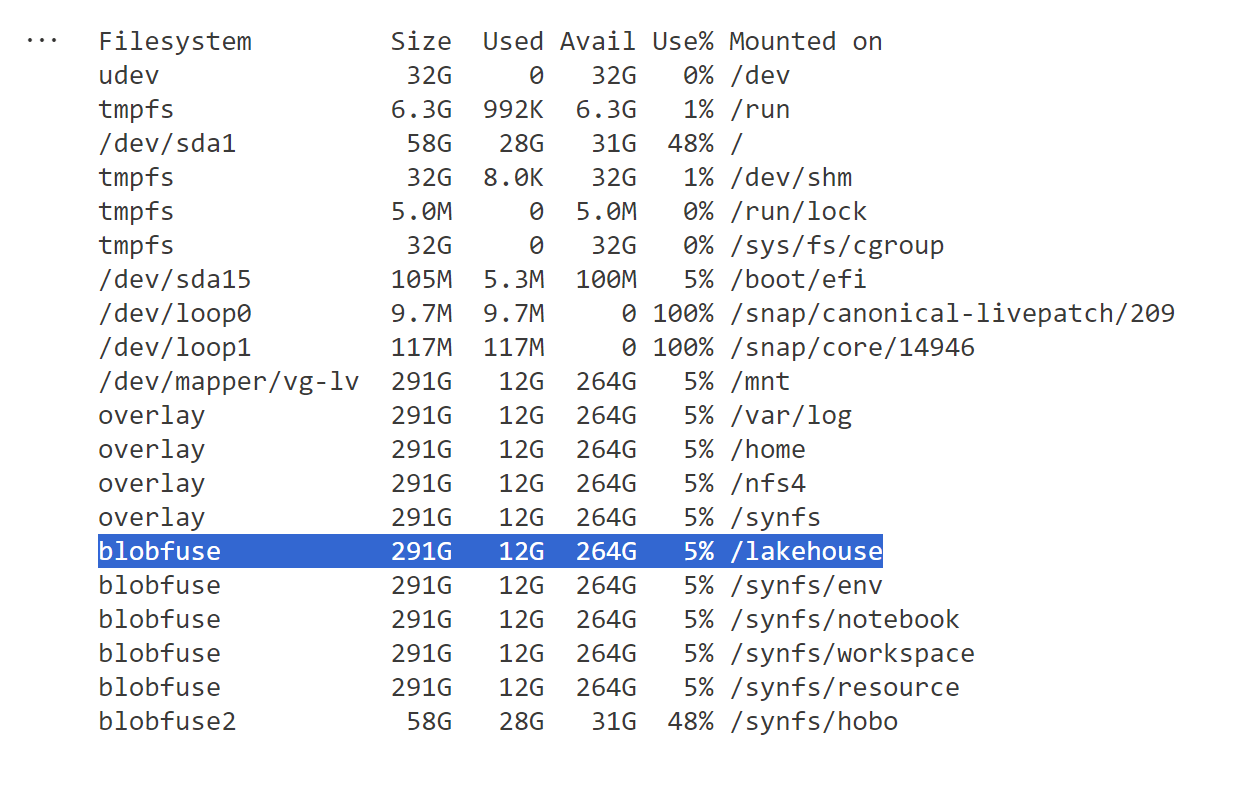
Getting average resource usage consumption
In Fabric capacity metrics, go to a hidden tab “TT Operation Data”
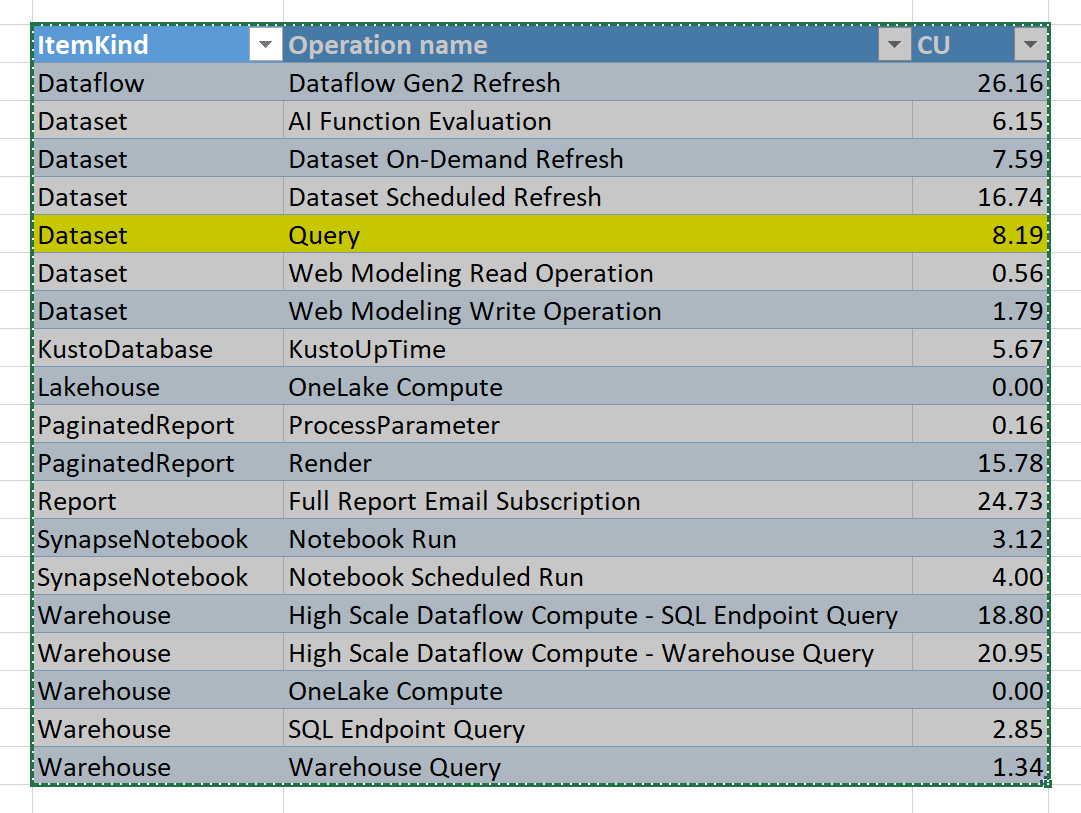
Copy it to a new tab, and you will get something like this
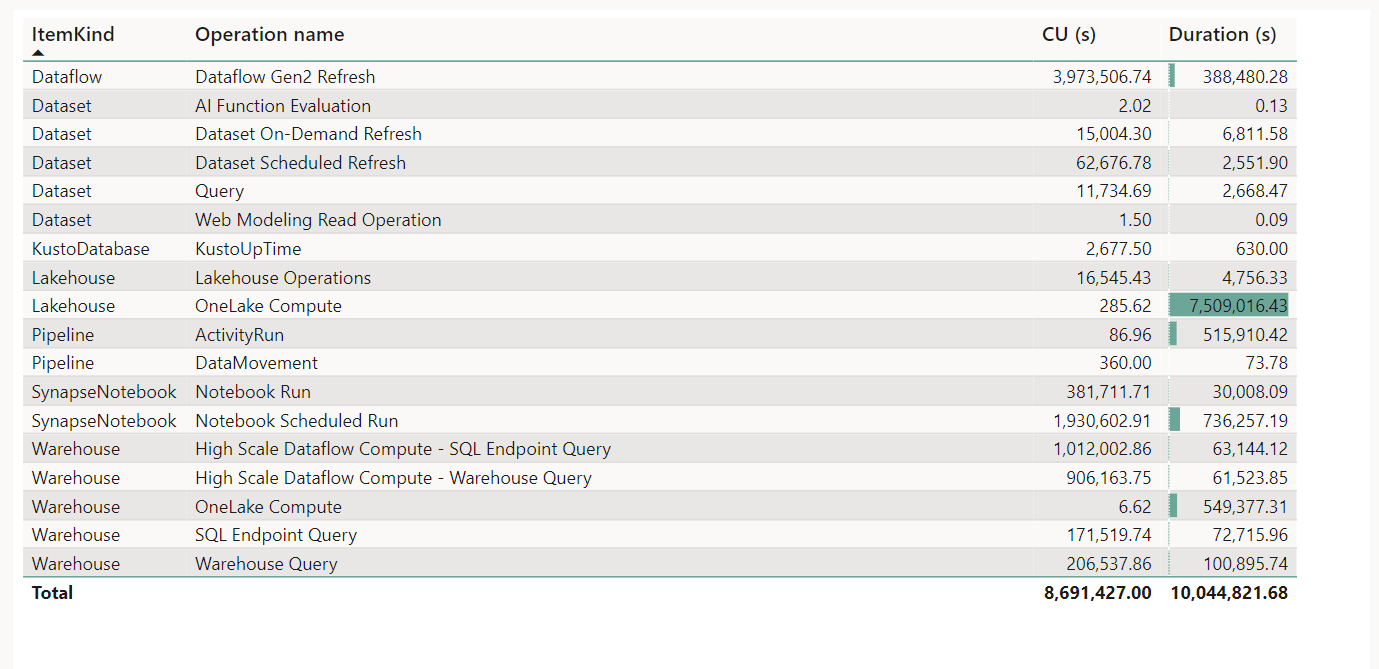
The table Operationsnames is hidden in the model, so I can’t build a customized report, anyway just for the purpose of this blog, I will just export to Excel ( God bless excel).
The compute unit is simply CU(s)/Duration, and to get a feeling about the numbers, let’s convert CU which is basically a virtual unit to a dollar figures, it is just for demonstration purpose only, P1 is a committed resource, regardless of the usage, the you pay a fixed 5000 $/Month and you get 64 CU
So 1 CU= 5000 $/30 day/24 Hours/64 CU= 0.10 $/Hour
F SKU which is a Fabric capacity bought from Azure is more expensive but it has zero commitment and you can suspend it anytime.
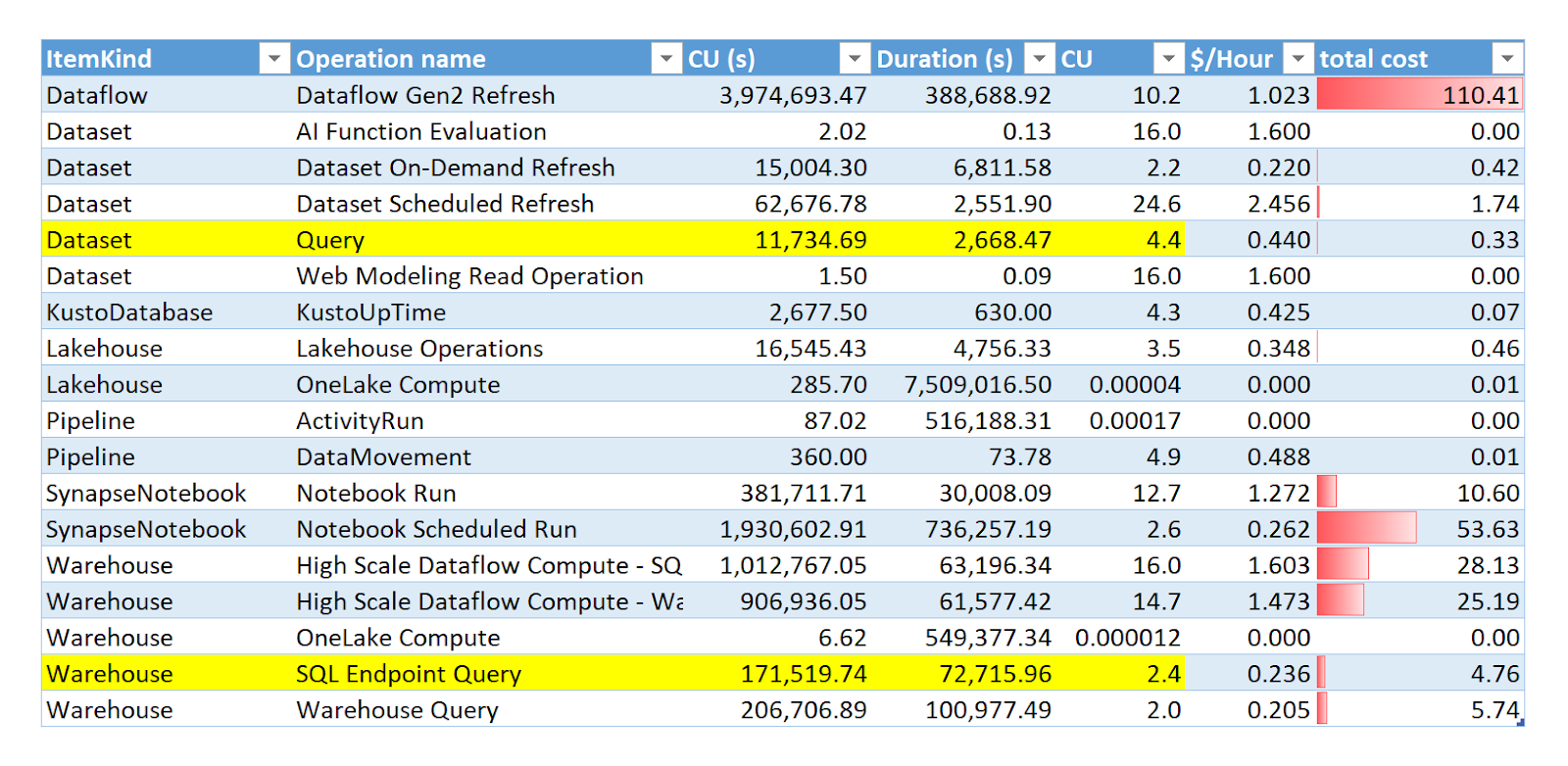
Just to show that the resource assignment is not fixed, here is an example from our production instance ( I have no idea yet, what is High Scale Dataflow compute)
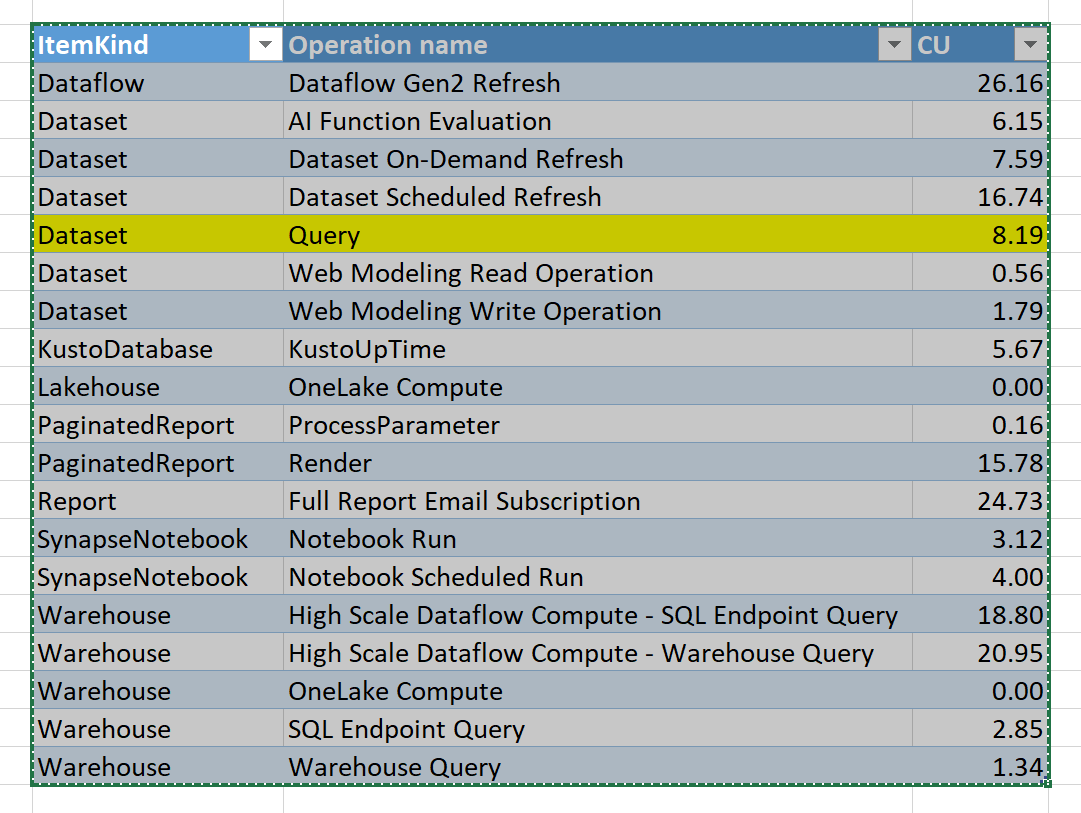
Can we configure resources assignments ?
No you can’t, Fabric assign the necessarily resources automatically, the only exception is Spark
Do all Engines have the same efficiency ?
That’s a tricky questions and to be honest, it does not matter in practise, most of the engines don’t really overlap, so it is not a useful comparison, but we have an interesting exception, Fabric Notebook and Dataflow Gen2 can be both used for an ETL job, I think it will be an interesting hot topic 🙂
Still you did not answer which Engine is cheaper ?
I don’t know, build a Proof of concept with a realistic workload and see for yourself, personally after using fabric for the last 5 Months, I can say the following
- Notebook can be very cheap, just assign one node compute.
- SQL Engine is very competitive
- Dataflow Gen2 is probably the less mature offering in Fabric and can act in some unexpected ways.
- Orchestration using Pipelines is virtually free 🙂