The October release of PowerBI Desktop introduced a very interesting feature, Top N filtered is pushed down for Direct Query Sources, I thought I may give it a try and blog about it, for some reason it did not work, which is great for the purpose of this blog as if you came from a SQL Background you will be surprised how PowerBI DAX Engine Works.
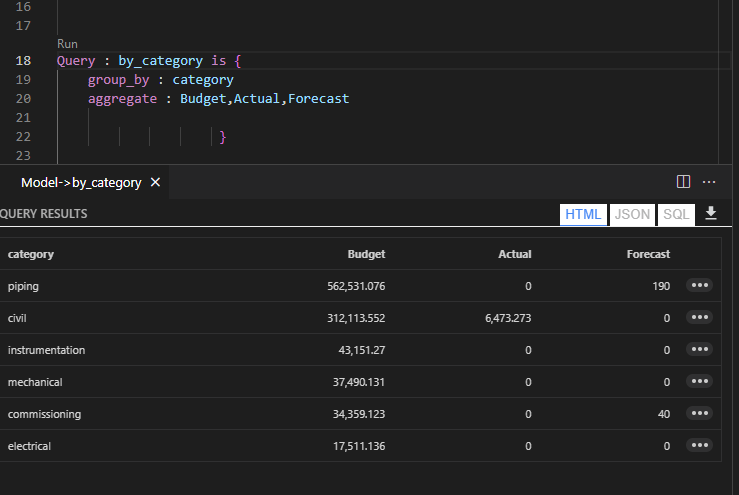
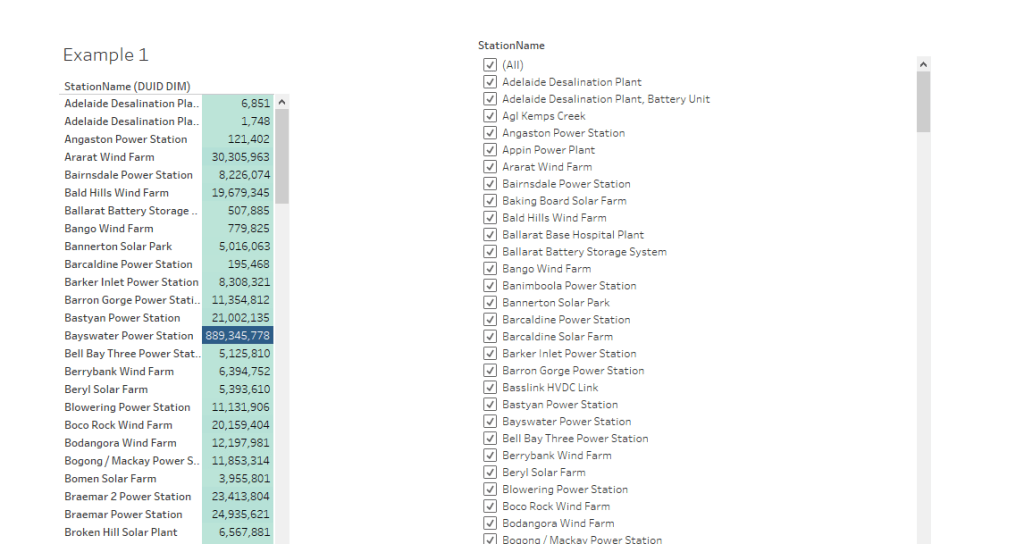
let’s try with one table in BigQuery as an example, and ask this Question, what’s the top 5 Substation by Electricity produced, in PowerBI, it is a trivial exercise, just use the Top N filter
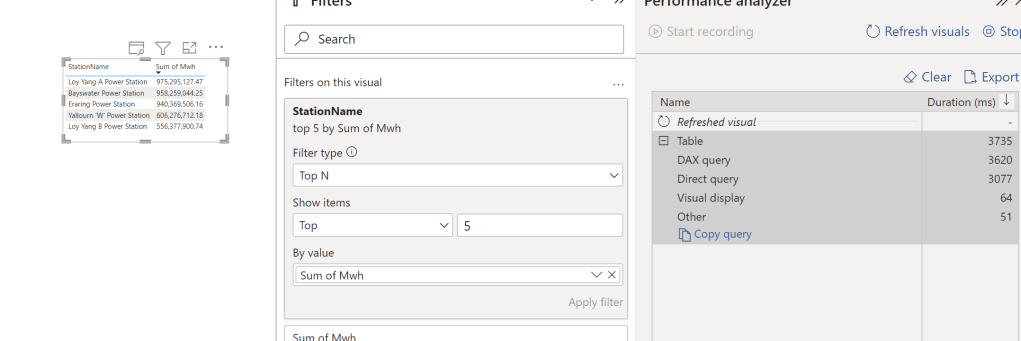
First Observation, 3.7 Second seems rather Slow, BigQuery or any Columnar Database should return the results way faster, specially that we are grouping by low cardinality columns ( around 250 distinct values)
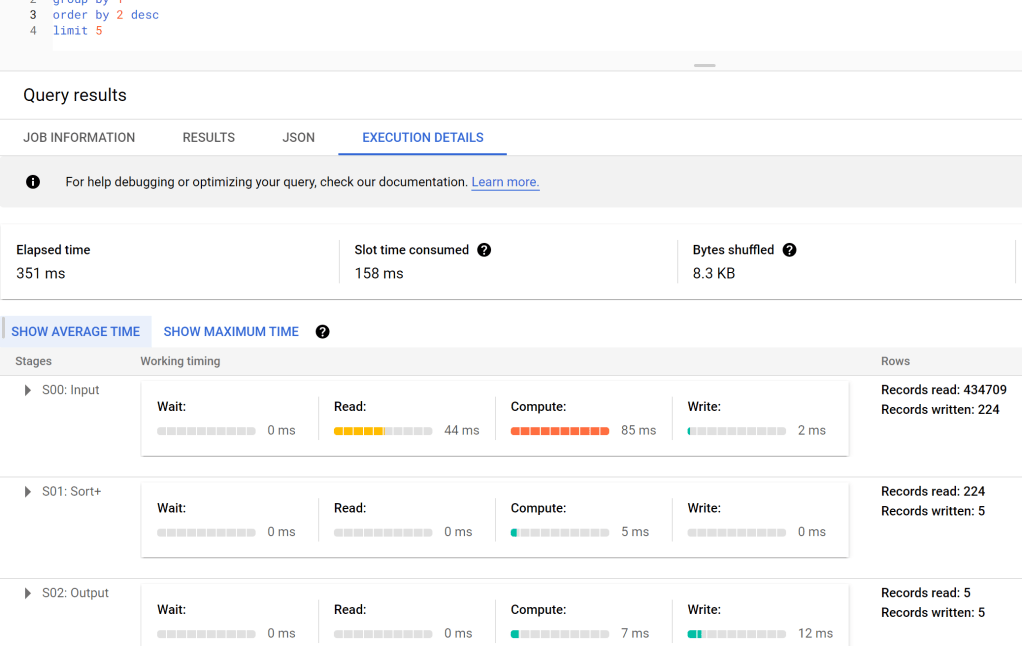
Let’s try SQL Query in BigQuery Console
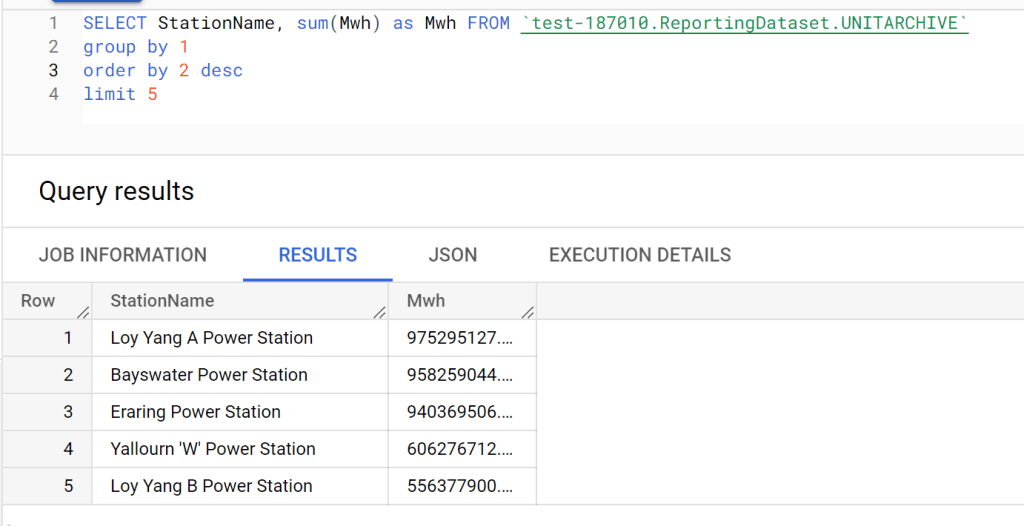
And let’s check the duration, 351 ms, the table has 91 Million records, that’s not bad at all, but we need to account for the data transfer latency to my laptop, still that does not explain the difference in duration !!!
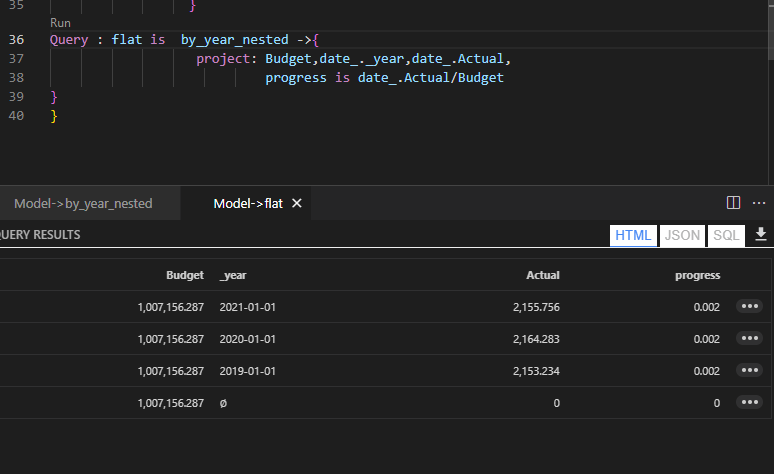
DAX Engine Query Plan
let’s have a look at the Query Plan generated by DAX Engine using the excellent free tool, DAX Studio
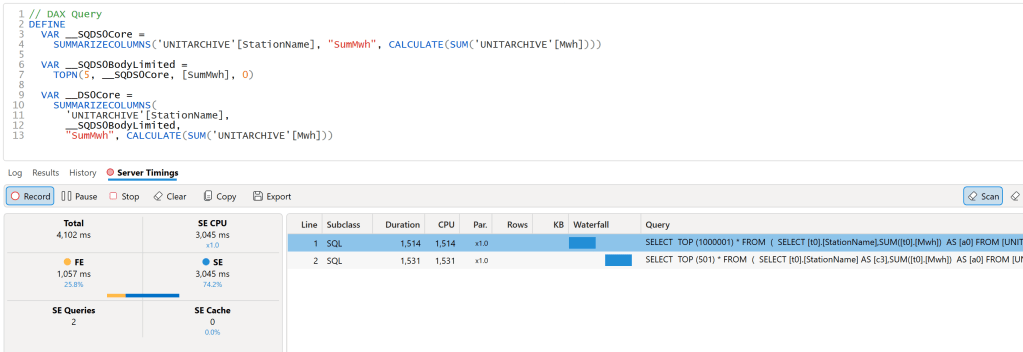
That’s very strange, 2 SQL Query and 1 Second spent by the Formula Engine, and the two SQL Queries are not even in parallel
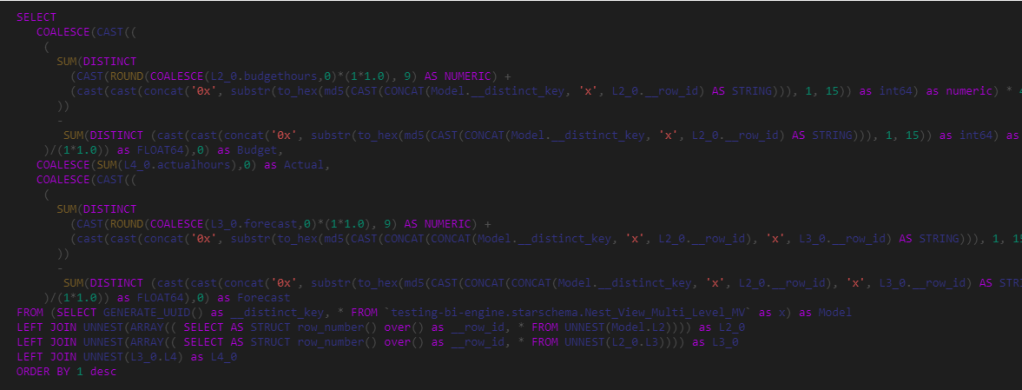
Looking at the SQL Queries, I think this is the logic of the Query Plan
- Send a SQL Query to get the list of all the substation and the sum of of MWH.
- Order the result using the Formula Engine and select 5 substation.
- Send another SQL Query with a filter of those 5 substation
Probably you are wondering why this convoluted Query Plan, Surely DAX Engine can just send 1 SQL Query to get the results, why the two trips to the source system, which make the whole experience slow.
Vertipaq Don’t support Sort Operator
Vertipaq which is the internal storage engine of PowerBI does not support the sort operator, hence the previous Query do make sense if your Storage engine don’t support sort.
But My Source do support Sorting ?
That’s the new feature, DAX Engine will generate a different plan when the source system do support sorting.
Great, again , Why Vertipaq don’t support sort Operator ?
No idea, probably only a couple of engineers from Microsoft Know the answer.
Edit : 23 October 2022
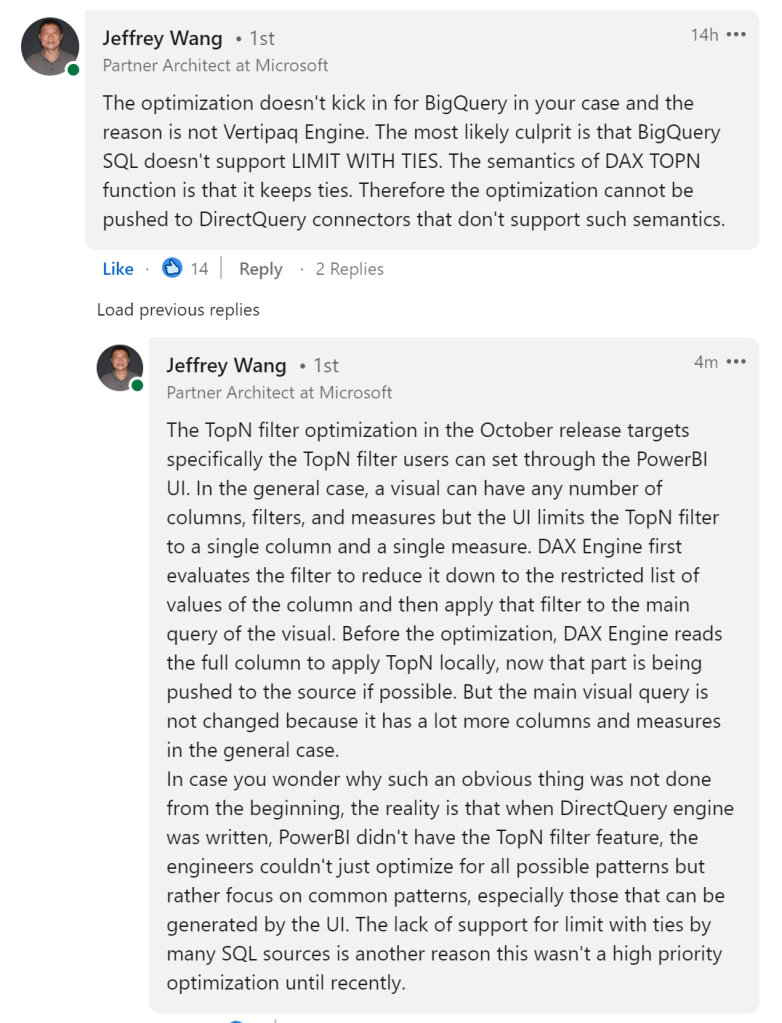
Jeffrey Wang ( One of the Original Authors of DAX Engine) was very kind and provided this explanation why the optimization did not kick in for BigQuery