With the recent release of Deltalake Python,we can write to Fabric Onelake using a local Path, using this new functionality, I updated a notebook I had built previously to show quick stats for all the tables in a particular lakehouse, it is using pure Python, so not only it works in Fabric but offline too in your local machine.
You can download the notebook here
All you have to do is to import the notebook and attach the lakehouse you want to analyze.
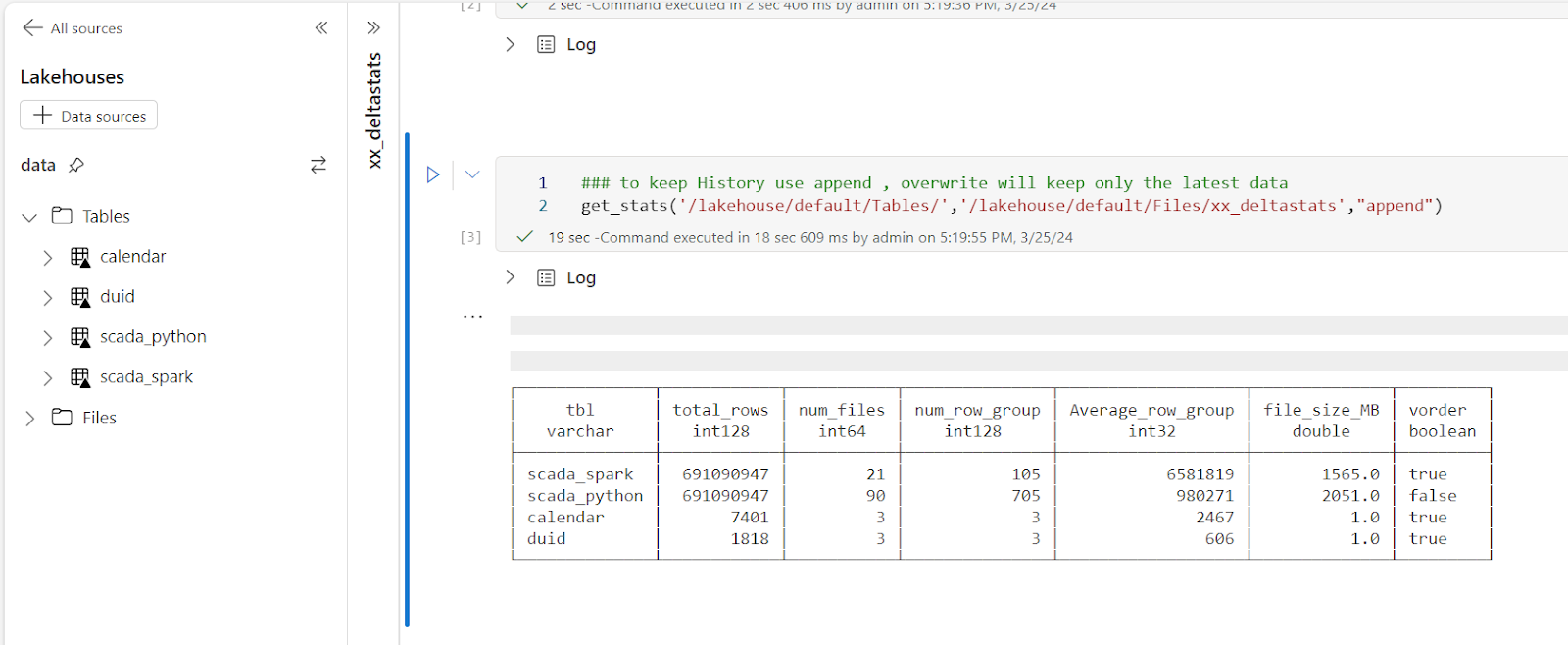
You can use append to keep the history.
It is using two packages
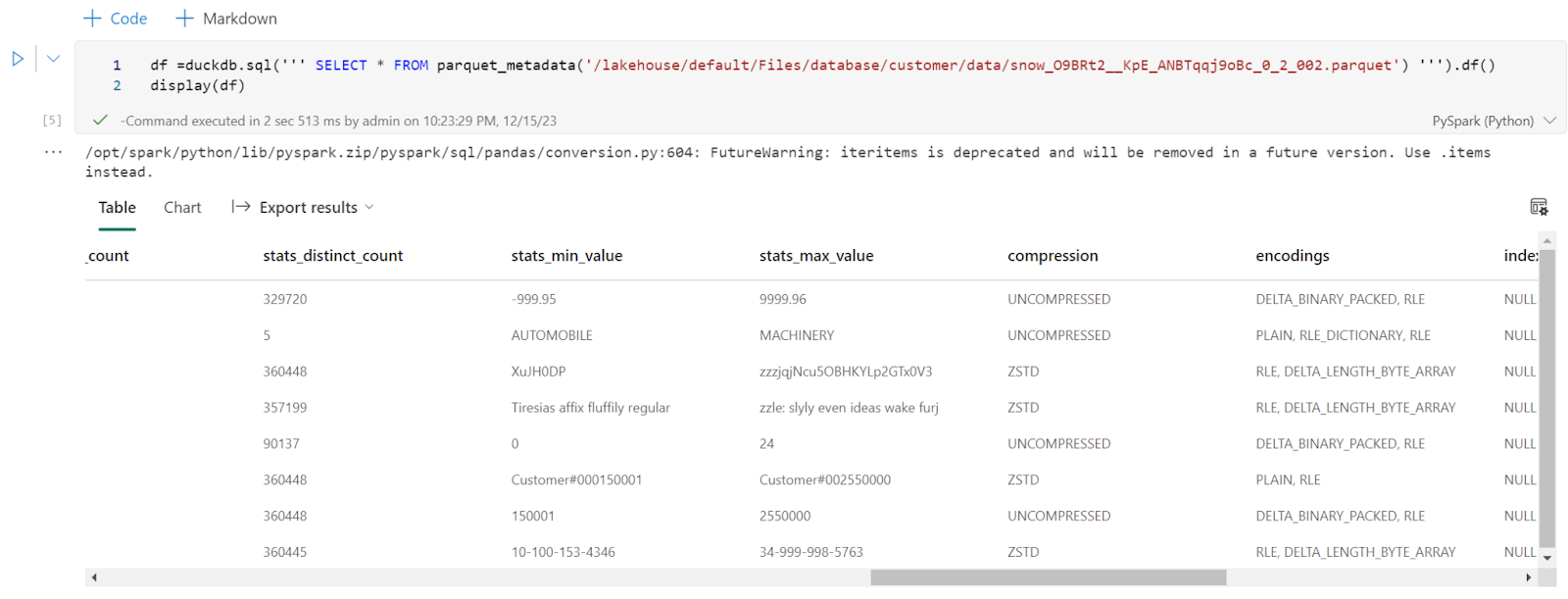
Delta Lake Python to get the delta stats
DuckDB to get the Parquet stats ( number of row groups)
And a SQL Query to combine the results from the two previous packages 🙂
The notebook is very simple and show only the major metrics for a Table, total rows, number of files, number of row groups and average row per row group, and if V-Order is applied
If you want more details, you can use the excellent delta analyser
Why you should care about Table stats
Fabric Direct Lake mode has some guardrails as of today for example, the maximum number of row groups in a table for F SKU less than F64 is 1000, which is reasonably a very big number but if you do frequent small insert without Table maintenance you may end up quickly generate a lot of files ( and row groups), so it is important to be aware of the table layout, especially when using Lakehouse, DWH do support automatic Table maintenance though.
Parting Thoughts
Hopefully in the near future, Lakehouse will expose the basic information about Tables in the UI, in the meantime, you can use code as a workaround.